NVIDIA Releases Fine-Tuning Guide for Cosmos Predict 2.5 Video Model
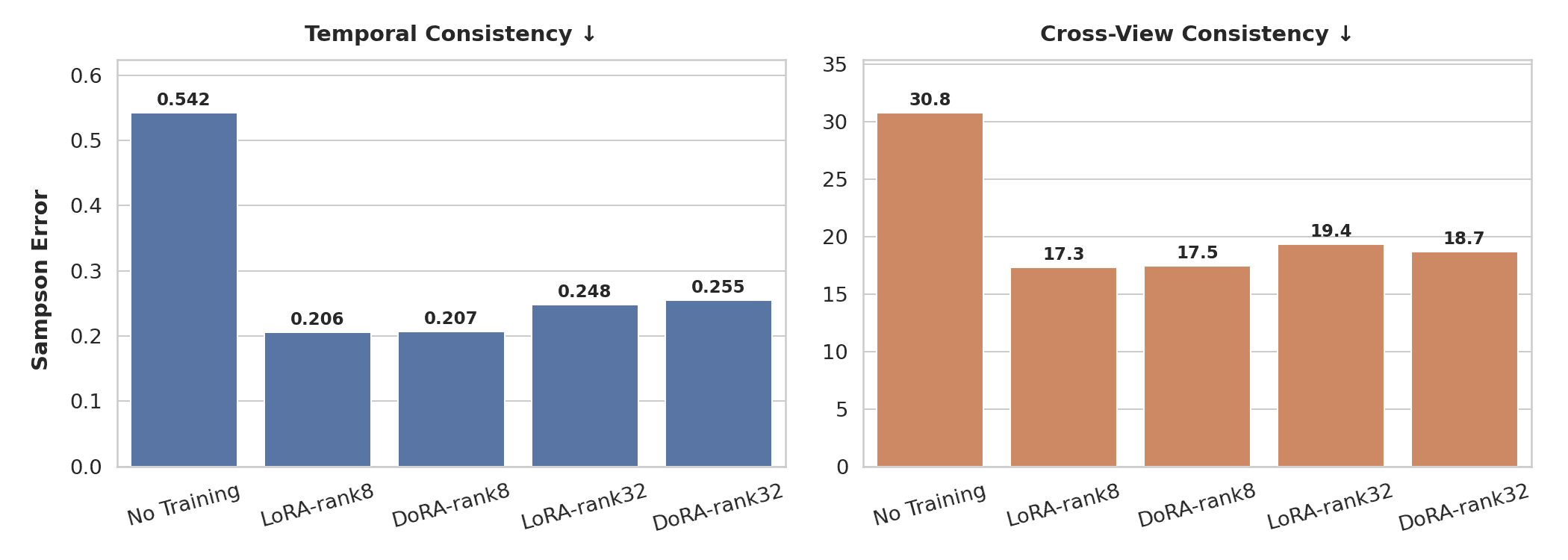
NVIDIA has published a technical guide on Hugging Face detailing how to fine-tune its Cosmos Predict 2.5 world model using parameter-efficient methods, specifically LoRA (Low-Rank Adaptation) and DoRA (Weight-Decomposed Low-Rank Adaptation). The documentation is aimed at research and engineering teams working on physical AI applications who want to adapt the model to their own data without the computational expense of training from scratch.
Cosmos Predict 2.5 is part of NVIDIA's broader Cosmos family of world foundation models, designed to generate physically plausible video sequences. Unlike general-purpose video generators, these models are built with simulation and robotics in mind - the idea being that a robot or autonomous system can use generated video as a proxy for real-world experience during training or evaluation. Fine-tuning such a model on domain-specific footage, such as a particular robot platform or industrial environment, can meaningfully improve the realism and relevance of the generated sequences.
LoRA and DoRA are both techniques that reduce the number of trainable parameters during fine-tuning by decomposing weight updates into lower-rank approximations. DoRA extends LoRA by separately handling the magnitude and direction components of weight matrices, which can improve training stability and final model quality in some settings. Using either approach, teams can adapt a large pretrained model on relatively modest hardware compared to full fine-tuning, making the process more accessible to organizations without large GPU clusters.
The guide walks through the practical steps involved: dataset preparation, configuration of the LoRA or DoRA training setup, and how to run the fine-tuning process against the Cosmos Predict 2.5 base weights. By hosting the documentation on Hugging Face, NVIDIA is positioning the workflow within an ecosystem that many ML practitioners already use for model management and sharing, which lowers the barrier to getting started.
The release reflects a broader push to make world models usable outside of NVIDIA's own research environment. Physical AI - encompassing robotics, autonomous vehicles, and related fields - increasingly relies on synthetic video data for training and validation, and fine-tunable world models are a practical tool for generating that data in a controlled, domain-relevant way. Making the fine-tuning process explicit and documented is a step toward wider adoption among teams that may not have the resources to develop such pipelines independently.


